🌿 What?
-
Bất kỳ sự kiện nào gây ảnh hưởng tiêu cực tới quá trình nghiệp vụ liên tục hoặc vấn đề tài chính của một công ty thì đó được gọi là disaster(hay còn được gọi là incident)
-
Disaster Recovery(DR) là các hoạt động được chuẩn bị để thực hiện quá trình hồi phục sau khi xuất hiện một disaster.
-
Các loại DR:
- On-premise => On-premise: thuê một datacenter đặt ở Hà Nội, một cái đặt ở Hải Phòng chẳng hạn.
- On-premise => Cloud: Hybrid Recovery - có một máy chủ vật lý đặt ở cty, thuê thêm datacenter trên cloud, nếu on-premise có vấn đề thì switch qua cloud sài.
- Cloud Region => Cloud Region
-
Phân biệt 2 định nghĩa:
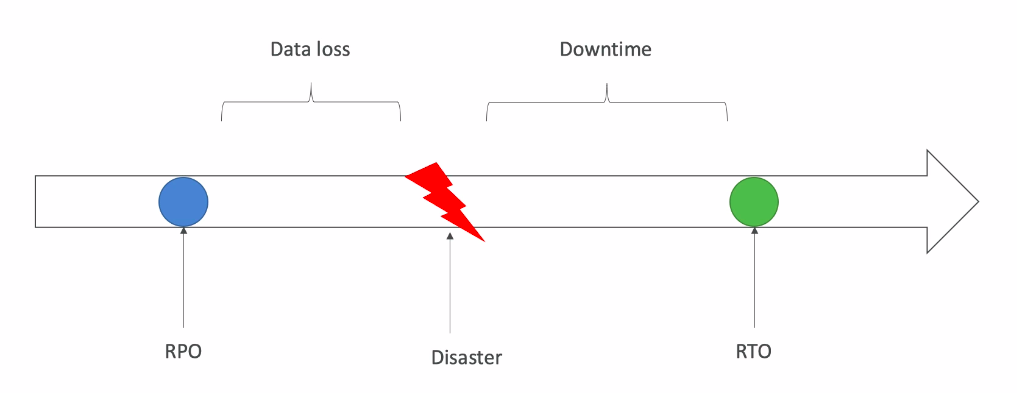
- RPO - Recovery Point Objective - bao nhiêu dữ liệu bị mất khi xảy ra disaster
- RTO - Recovery Time Objective - thời gian downtime là bao lâu kể từ thời điểm phát sinh disater.
=> Việc của chúng ta làm làm cách nào đó tối ưu Data loss và Downtime càng nhỏ càng tốt.
🌿 Strategies
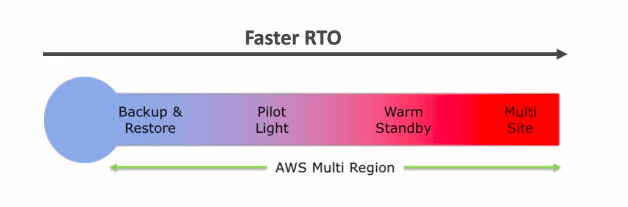
- 4 strategies sắp xếp theo thời gian Downtime, cũng như giá tiền, càng đắt thời gian Downtime càng nhỏ.
🍃 Backup and Restore (High RPO)
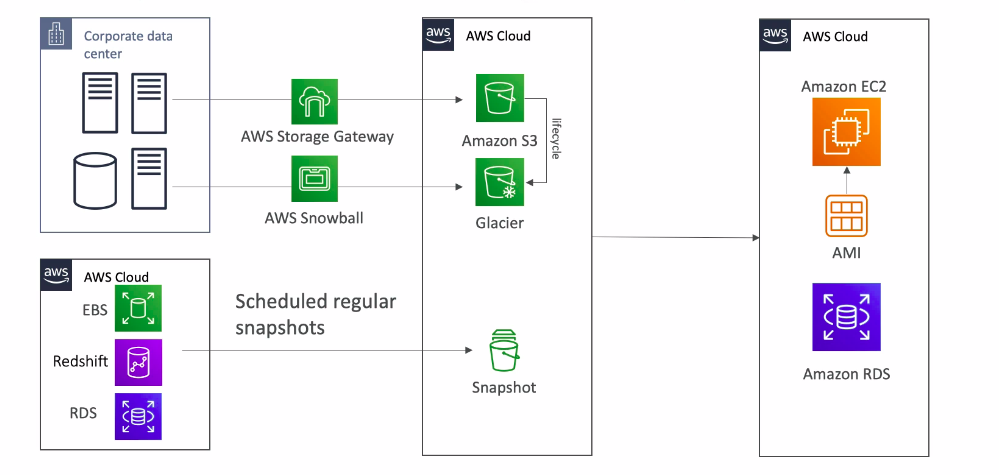
- Đặt lịch để datacenter tự động tạo snapshot, hoặc với on-premise thì gửi dữ liệu lên Cloud. Cách này thì không cần setup gì nhiều, giá còn rẻ.
- Cơ mà cách này thì nó dễ High RPO và RTO khi có disaster.
- Vd như dùng AWS Snowball để chuyển dữ liệu tầm 7 ngày, trong thời gian di chuyển, on-premise nó cháy phát, thế là mất toàn bộ data trong 1 tuần luôn.
- Hoặc tạo snapshot 24h hoặc 1h một lần thì nếu có disaster, hệ thống cx sẽ mất toàn bộ dữ liệu trong thời gian countdown đó.
- Ngoài ra còn một số hạn chế cần xem xét khi triển khai:
- Mất thời gian và tài nguyên để thực hiện sao lưu.
- Không thể khôi phục ngay lập tức, khi xảy ra disater, dữ liệu chưa thể sử dụng ngay được mà sẽ có một khoảng downtime để khôi phục lại dữ liệu.
- Nói là rẻ nhưng chúng ta cũng phải mất thêm phí để trả cho việc lưu trữ, băng tần sao lưu, …
🍃 Pilot Light
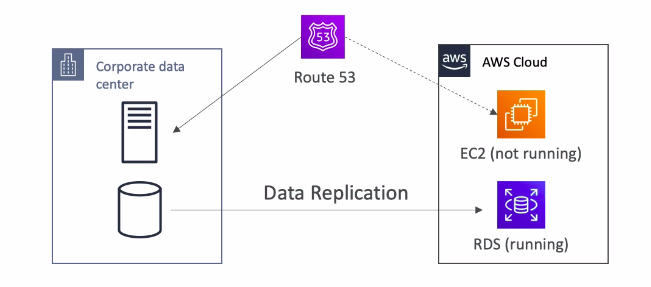
- Là chiến lược duy trì một bản sao của hệ thống, bản sao này sẽ chỉ bao gồm các phần quan trọng của hệ thống(vd như RDS, EC2 thì lúc nào sử dụng tạo sau nên không cần), duy trì ở mức tối thiểu để tối ưu chi phí.
- Như ví dụ trên, khi disaster xảy ra, hệ thống sẽ điều hướng để chạy trên bản sao, từ đó giúp giảm thiểu RTO, cũng như dữ liệu luôn được nhân bản liên tục, giảm thiểu RPO.
- Hạn chế:
- Chi phí để duy trì bản sao
- Cần có một kế hoạch chi tiết để thực hiện hồi phục nhanh chóng và chính xác. Chiến lược này liên quan nhiều đến cấu hình, kích thước, tài nguyên, network, và nhiều yếu tố khác của hệ thống.
🍃 Warm Standby
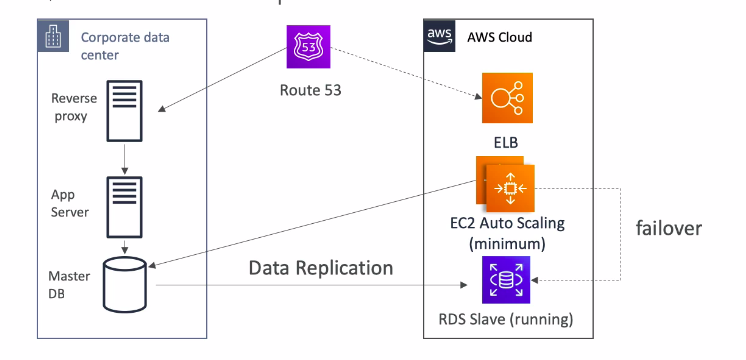
- Giống Spot Light, cũng duy trì một bản sao dự phòng nhưng bản sao này sẽ chạy thêm cả các dịch vụ chính của hệ thống.
- Bên trên không chạy EC2 Instances thì chiến lược này sẽ có chạy sẵn để tạch thì chạy luôn, chứ không có downtime để launch EC2 Instance nữa.
- Hạn chế:
- Chi phí tất nhiêu là nhiều hơn rồi, đắt luôn ấy chứ.
- Có thể bản sao sẽ không đáp ứng được đầy đủ lượng traffic của hệ thống cũ, lúc này thì vẫn cần thời gian để scale trước khi hoàn toàn ổn định.
🍃 Multi Site
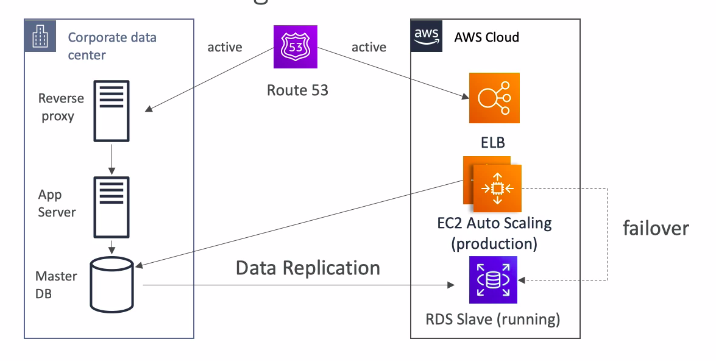
- Phiên bản khô máu, chạy song song 2 phiên bản poroduction luôn, nó cái nào gặp lỗi, điều hướng qua cái còn lại để sử dụng.
- Rất đắt.
- Downtime hầu như rất thấp mấy giây, cùng lắm là mấy phút thôi.
🌿 Tips
- Backup
- High Availability
- Dùng Route53 để migrate DNS trên nhiều Regions.
- RDS/ElastiCache Multi-AZs, EFS, S3, …
- Site-to-site để recovery cho Direct Connect
- Replication
- Automation
- CloudFormation/Elastic Beanstalk để tạo lại toàn bộ hệ thống trên môi trường mới.
- Recover/Reboost thông qua CloudWatch nếu nó có alarm lỗi.
- Dùng AWS Lambda Function để thực hiện tự động các tác vụ chỉ định.
- Chaos
- Kiểm thử, như Netflix đặt toàn bộ tài nguyên trên AWS Cloud, có một thuật ngữ “simian-army”. Là kiểu kiểm thử khả năng DC của hệ thống - random terminate EC2 của production luôn chứ không phải của môi tường test luôn =)))